뒤늦게지만 ChatGPT에게 코딩을 시켜 보았다. 명령어 하나하나마다 어떤 기능을 하는 건지 설명하는 주석도 잘 달아 주고 아주 친절하게 짜 준다.
처음엔 어느 정도 개선의 여지가 있는 프로그램을 만들어 주는 것 같지만, 간단한 말로 피드백을 주면 알아서 잘 반영하고 디버깅한다.
생각보다 재미있고 놀랍다. 무료 버전(3.5)인데도 말을 잘 알아들어서 신기하다.
언어와 매체 국어 문법 시간에 익히 배워 알고 있듯이, 한국어의 예사소리(평폐쇄음과 평파찰음)는 유성음 사이에서 유성음으로 바뀐다.
예를 들어 /ㄱ/은 어두에서 무성파열음 [k]로 실현되지만, 유성음 사이에서는 유성파열음 [g]로 실현된다.
이 규칙을 적용하여,
/k/ 등을 받아서 그 앞뒤에 있는 음소가 유성음인지 체크하고 그들이 유성음이면 /k/도 유성음 [g]로 바꾸는 프로그램을 짜 보도록 ChatGPT에게 명령하였는데, 결과가 아주 흥미롭다.
우선 임의의 음소를 받아서 그 음소의 음운 자질을 모두 담은 자질 매트릭스를 출력하는 프로그램을 짜 보도록 했다.
나: Please create a program that takes input for a phoneme and generates a phonological feature matrix.
ChatGPT 3.5: Creating a comprehensive phonological feature matrix involves a deep understanding of the linguistic properties of each phoneme. Here's a simple Python script that allows you to input a phoneme and generates a basic phonological feature matrix. Note that this script is quite basic and might not cover all possible features.
... [코드] ...
This script uses basic phonological features; you may need to expand or modify it based on the specific phonological features relevant to your language.
결과물은 생각보다 인상적이었다.
모든 음운 자질에 '-'를 넣어서 초기화한 다음,
(아마도 영어의) 모든 음소 목록을 가지고 음소를 하나씩 프로그램에 입력해서,
입력된 음소가 무엇이냐에 따라 해당하는 자질만 '+'로 바꾸는 식이었다.
코드 안에서 음소는 IPA기호로 표기되어 있었는데, 'IPA 기호를 모두 X-SAMPA로 바꿔 줘'라고 하니 순식간에 X-SAMPA로 된 프로그램을 짜 주었다.
입력값을 받는 부분도,
원래는
input_phoneme = input("Enter a phoneme: ").strip()
이었다가
input_phoneme = input("Enter a phoneme (X-SAMPA): ").strip()
로 바뀌었다.
내가 그러라고 말한 적도 없는데... 이 얼마나 세심한 배려인가!
다만 세세한 내용을 보면 틀리거나 주의가 필요한 곳도 상당히 있었다. (어느 언어의 음운 체계인지 밝혀 주지 않았다는 사정을 참작해 줄 만하긴 하다.)
모음의 경우 전설 모음과 후설 모음은 잘 구분했지만
고모음과 중모음과 저모음은 거의 구분하지 못했고, (ɛ, æ, ɔ, ɑ 등에 전부 +high 자질을 설정했다.)
자음의 경우 내가 알기로 /θ/와 /ð/는 sibilant도 아니고 strident도 아닌데, 두 자음에 +strident 자질을 설정하고 있었다.
또 영어나 한국어라면 모든 모음의 voiced 자질이 '+'여야 할 텐데, 모음을 만났을 때 voiced 자질을 '+'로 바꾸는 명령이 들어 있지 않았다.
그래서 다음 과제에서 모음을 유성음으로 인식하지 못하길래, 이 부분 코드는 수기로 바꿔 줬다.
다음 과제란 이것이었다.
위에서 말했듯이 한국어의 평폐쇄음과 평파찰음은 유성음 사이에서 유성음으로 바뀐다.
예를 들어 /ㄱ/은 어두에서 무성파열음 [k]로 실현되지만 유성음 사이에서는 유성파열음 [g]로 실현된다.
우선 몇 가지 간단한 명령어로 프로그램이 받는 입력과 내는 출력을 음소가 아닌 음절로 바꾸도록 한 뒤에,
한국어의 이러한 유성음화 규칙을 적용하는 프로그램을 짜 보라고 ChatGPT에게 명령해 보았다.
나: what about a program that takes input for a syllable, converts each phoneme of that syllable into a feature matrix, and changes every voiceless consonants(...지금 보니 복수형으로 썼었군) into voiced ones(이것도...) when they're between voiced phonemes?
ChatGPT: Certainly! Here's a Python script that takes input for a syllable, converts each phoneme of that syllable into a feature matrix, and changes every voiceless consonant between voiced phonemes to its voiced counterpart:
...[코드]...
This script first converts each phoneme of the input syllable into its feature matrix using the generate_feature_matrix function. Then, it checks for voiceless consonants between voiced phonemes and changes them to their voiced counterparts. Note that this script assumes space-separated phonemes in the input syllable. Adjustments may be needed based on the format of your input data.
아까 짰던 자질 매트릭스 생성 프로그램을 활용해 음절에 있는 모든 음소의 자질 매트릭스를 만들어낸 다음,
반복문에서 받은 음소의 바로 앞 음소와 바로 뒤 음소의 유성성 자질을 체크하고,
둘 다가 '+'이면 해당 음소를 유성음으로 바꾸는 방식이었다.
근데 유심히 보니 좀 의아한 구석이 있었다.

이 어리석은 친구가,
기껏 만들어 놓은 자질 매트릭스 생성 프로그램을 활용할 생각을 못 하고,
굳이 무성음 p t k 를 열거해서 해당하는 유성음 b d g 로 바꾸는 명령어를 장황하게 쓰고 있었던 것이다.
(근데... 어리석은 건 명령을 충분히 주지 못한 내 쪽이었다. 후술)
이렇게 쓰면 코드가 길어져서 귀찮기도 하지만, (애초에 저렇게 해당하는 케이스를 하나하나 찾기 귀찮아서 프로그램을 쓰는 거니까)
저기에 열거되지 않은 /ㅈ/을 유성음화하는 데에는 실패하고 만다.
그래서 아래와 같이 피드백을 주었더니 흥미로운 반응을 보였다.
나: you should use the feature matrix instead of listing all possible voiceless phonemes and their counterparts.
ChatGPT: Certainly! You're right; using the feature matrix makes the script more flexible. Here's the updated script:
(앞부분 생략)
def convert_voiceless_to_voiced(syllable):
phonemes = syllable.split()
result = []
for i in range(len(phonemes)):
if i > 0 and i < len(phonemes) - 1:
# Check if the current phoneme is a voiceless consonant
if generate_feature_matrix(phonemes[i])['Voiced'] == '-' and generate_feature_matrix(phonemes[i-1])['Voiced'] == '+' and generate_feature_matrix(phonemes[i+1])['Voiced'] == '+':
# Change voiceless consonant to its voiced counterpart
voiced_variant = generate_feature_matrix(phonemes[i])
voiced_variant['Voiced'] = '+'
# Find a voiced counterpart based on the feature matrix
for voiced_phoneme, features in feature_matrix.items():
if features == voiced_variant:
result.append(voiced_phoneme)
break
else:
result.append(phonemes[i])
else:
result.append(phonemes[i])
return ' '.join(result)
(뒷부분 생략)
This modification uses the feature matrix to determine the voiced counterpart of voiceless consonants dynamically. The script iterates through the feature matrix to find a matching voiced phoneme based on the features.
왠지 모르게 뿌듯함이 느껴지는 장면이었다. ChatGPT가 놓친 걸 내가 잡아내서 피드백을 주다니!
어쨌든 저렇게 자연언어로 간단하게 피드백을 주었는데도 곧장 알아듣고 반영한다는 게 아주 신기하다.
눈치 빠르고 일 잘하는 부하를 부리는 느낌이랄까...
어쨌든 흥미로운 경험이다.
...라고 쓰고 글을 마치려고 했는데,
막상 위에 올린 코드를 실행시켜 보니 오류가 났다.
왜냐면 내가 맨 처음 요구한 바에 따라 ChatGPT가 성실히 작성한 generate_feature_matrix() 함수는,
음소를 입력받아 음운 자질 매트릭스를 출력하는 함수이지,
음운 자질 매트릭스를 입력받아 음소를 출력하는 함수가 아니었기 때문이다.
그런 함수를 가진 프로그램은 애초에 내가 만들어 달라고 한 적이 없었다.
그러니까 내가 마지막에 요구한 대로 유성음 사이에 있는 무성음의 voiced 자질을 '+'로 바꿔 놓더라도,
이 프로그램은 그렇게 바뀐 음운 자질 매트릭스로부터 그에 해당하는 음소를 찾아낼 수가 없었던 것이다.
그래서 다시 아래와 같이 피드백을 주었다.
나: The program you just gave me doesn't work because it can't convert a feature matrix into a phoneme.
그리고 ChatGPT는 순식간에 자질 매트릭스로부터 음소로 reverse mapping을 해내는 프로그램을 만들어 주었다.
ChatGPT: I apologize for the oversight. To address this issue, we need to create a reverse mapping from feature matrices to phonemes. This will allow us to look up the voiced counterpart based on the feature matrix. Here's the updated script: (...)
하는 김에 아까 내가 수기로 바꿔 놓았던 부분,
즉 모음에도 유성성을 부여하도록 하는 디버깅을 같이 시켰더니 그것도 만족스럽게 잘 해냈다.
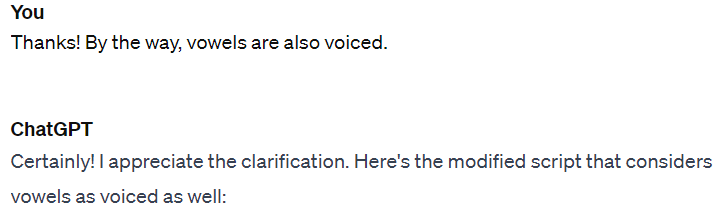
...[코드]...

마지막으로 만들어진 결과물의 성능은 이렇다.

X-SAMPA로 '아기/aki/'를 입력하니까 [agi]를 출력하는 모습이다.
결론적인 감상: 언젠가 이런 작업이 필요할 때 초벌로 틀을 잡는 용도 정도는 충분히 되는 것 같다. 유료 버전은 내용적인 오류 측면에서 얼마나 개선이 있을지 궁금하다. 조만간 유료 버전도 한번 써 볼까 싶다.
++ 한두 시간 더 만져 보고 느낀 건... 결국 스스로 코드를 한 줄 한 줄 다 읽어 가면서 뜯어봐야 한다는 점이다.
탈비음화(denasalization)를 구현해 보고 싶었는데 도무지 안 돼서 모든 음소의 feature matrix를 출력해서 하나하나 뜯어본 결과는 허무하게도...
챗지피티는 자질값에 '마이너스'를 넣을 때 대시(dash) 기호를 사용했고
나는 코드를 수정할 때 하이픈(hyphen) 기호를 사용한 것이었다.
Visual Studio에서는 도저히 안 보여서 지푸라기라도 잡는 심정으로 메모장에 복사 붙여넣기 해 보았더니
충격적이게도 이런 비주얼이었다. (알고서 다시 봤더니 Visual Studio에서는 dash 기호에 경고문을 붙여 주고 있더라...ㅋㅋ)

위와 아래의 내용이 서로 완전히 똑같아야 하는데 위에서는 Sonorant와 Nasal에 dash가 들어가 있고 아래에서는 hyphen이 들어가 있어서 문제가 됐던 것이다.
그래도 이 오류를 스스로 찾아내서 목표했던 걸 구현해 놓고 나니 굉장히 뿌듯하다^^
참고로 탈비음화인데 [+ dorsal]인 건 한국어를 생각하면 좀 뜬금없는데, 그냥 한국어랑은 상관없이 특정 환경에서 N(연구개 비음)을 g(연구개유성파열음)로 바꾸는 걸 보고 싶었다.
이렇게 오류가 뜨거나 프로그램이 내가 원했던 대로 작동하지 않을 때는 print() 함수가 참 유용한 거 같다.
줄마다 얘가 뭘 하고 있는 건지,
그 줄에서 변수에 무슨 값이 들어 있는 건지,
조건문에 진입을 하긴 한 건지,
진입을 안 했다면 무슨 조건이 어긋나서 안 한 건지
print() 함수의 인자와 위치를 바꿔 가며 잘 확인해서 문제를 해결하고 나면 묘한 성취감이 느껴진다.
'언어학' 카테고리의 다른 글
| '빠르다~이르다'와 '느리다~늦다'의 비대칭 - 코퍼스, 의미 지도와 CLICS, 속도와 시점의 다의성 (6) | 2024.02.11 |
|---|---|
| "불 키고 자면 안 돼요" - '키다'는 왜 생겨난 걸까? (9) | 2024.02.10 |
| 구독자 분들께 보여드리고 싶은 영상 (7) | 2024.01.19 |
| [언어유형론] 교착어, 굴절어, 고립어(분석어) (1) | 2023.12.16 |
| 내용어와 기능어, 실질형태소와 형식형태소 - '대명사'는 어느 쪽? (2) | 2023.12.12 |