1. 사람은 발화 전체의 단위시간당 정보량을 일정하게 유지하려는 경향을 가지고 있다. -> '균일 정보 밀도' uniform information density라고 한다.
정보량이 많은 음절은 길게 발음하고 정보량이 적은 음절은 짧게 발음한다.
1.1. 구글 n-gram 데이터를 가지고 11개 유럽 언어의 단어들을 분석해 보니, 11개 언어 모두에서 정보량이 많은 단어일수록 (정서법 기준) 글자수가 많고, 정보량이 적은 단어일수록 글자수가 적다고 한다.
2. 심지어 똑같은 단어에 대해서도 그렇다.
같은 'nine'이어도, "I would like nine please"라는 말의 'nine'이 "a stitch in time saves nine"이라는 속담의 'nine'보다 훨씬 길고 careful하게 발음된다. (Lieberman 1963)
(왜냐면 후자의 'nine'은 매우 예측가능하고 따라서 정보량이 거의 없기 때문이다.)
3. 자주 등장하거나 예측가능한 부분의 발음이 축약된다(reduced)는 것은 단순히 길이가 짧아진다는 것만은 아니다.
자음을 약화lenition시키거나, [인접 음소에] 동화(coarticulation 동시조음? 위백의 1번 뜻일 듯)시키거나, 모음을 중설 중모음에 가깝게(centralization) 발음하거나 하는 일도, 자주 등장하거나 예측가능한 말을 발음할 때는 일어난다.
('... 때 일어난다'고 썼다가 흥미롭게도 의미가 꽤 다르게 읽히길래 바꿨다.)
---------------------------------------------
4. 음운 이웃(phonological neighbor)이라는 개념이 있다.
A라는 단어에(서) 음소 한 개를 탈락시키거나, 삽입하거나, 대체했을 때 B라는 단어가 만들어지면,
A와 B는 음운 이웃 관계에 있다고 말한다.
5. 음운 이웃이 많은 단어는 알아듣기 불편하다는 사실이 알려져 있다. (전에 블로그에서도 언급한 바 있다.)
'cat'이란 말을 들을 때, 조금만 시끄럽거나 부주의해도 그 음운 이웃인 'cap'으로 오해하거나 'hat'으로 오해할 수가 있다.
이렇게 상상해 보자.
단어가 여럿 있다. 이 단어들은 '듣는이의 머릿속'이라는 골대를 향해 움직인다. 이 골대는 아주 좁아서 딱 한 개의 단어만 들어갈 수 있는데, 음운 이웃을 많이 달고 다니는 'cat'이 골대에 들어가려고 하다 보니 'cap'도 방해하고 'hat'도 방해하는 것이다.
즉 '음운 이웃 밀도'가 높으면 목표 어휘와 그 이웃들 간에 경쟁이 일어나며, 따라서 듣는이가 이해하는 데에 시간도 더 걸리고 정확도도 떨어진다.
여기까지는 그렇게 놀랍지 않다.
6. 나한테 꽤 새롭고 신기한 사실은, 이렇게 듣기를 방해하는 '음운 이웃 밀도'가 말하기에서는 정반대 효과를 낸다는 것이다. 음운 이웃이 많은 단어를 말할 때는 시간도 덜 걸리고 실수도 덜 한다고 한다.
7. 이건 사실이라기보다 가설적인 모형에 가깝겠지만, 6에 대해 아래와 같은 설명이 제시되어 있다고 한다. (Dell and Gordon, 2003)
- 사람 머릿속엔 단어의 집합과 음소의 집합이 각각 있다.
- 사람이 말을 하려고 할 때 특정한 단어를 내뱉으려고 하면, 머릿속 단어 집합에서 그 단어가 '활성화(activate)'되는 동시에, 그 단어를 이루는 음소들도 머릿속 음소 집합에서 함께 활성화된다.
예를 들어 cat이라는 단어를 내뱉으려고 하면 cat이라는 단어가 활성화되는 동시에 /k/라는 음소, /æ/라는 음소, /t/라는 음소도 함께 활성화된다.
- 이때 활성화되는 /k/, /æ/, /t/ 음소는 자신이 구성하는 다른 단어들에게도 그 활성화를 전파(spread)한다.
예를 들어 /k/의 활성화는 'cap'이란 단어에도 전파되고, /t/의 활성화는 'hat'이란 단어에도 전파되며, /æ/의 활성화는 'cap'에도 'hat'에도 다함께 전파될 것이다. (동시에 각 음소로부터 cat을 향한 역전파도 함께 일어날 것이다.)
즉, cat의 활성화가 결과적으로 그 음운이웃인 hat과 cap의 활성화를 또한 불러오는 것이다.
- 활성화된 음운이웃 단어들은 자신을 구성하는 모든 음소에게 다시 활성화를 전파한다. 'hat'은 /h/, /æ/, /t/에게, 'cap'은 /k/, /æ/, /p/에게.
단순히 'cat', 'hat', 'cap' 세 개의 단어만 고려하더라도 이상의 시나리오에서 벌써 /k/는 두 번, /æ/는 세 번, /t/는 두 번 활성화되었다.
- 이렇게 강하게 활성화된 음소들은 다시 자신을 포함하는 모든 단어에 활성화를 전파하는데, 이때 맨 처음 활성화되었던 목표 단어 cat도 같이 활성화된다.
- 결과적으로 머릿속 단어 집합 안에서 가장 여러 번, 가장 강하게 활성화되는 것은 유일하게 cat뿐이 된다.
(- 써 놓고 보니까 '활성화'라는 말이 약간 속 편한 이론적 추상화인 듯 느껴지기는 한다.)
8. Dell et al.(1997)에 따르면 원래 말하기 과정에서 목표 단어의 산출을 방해하는 주된 경쟁자는 음운적으로 관련된 단어가 아니라 의미적으로 관련된 단어라고 한다.
(예를 들어 '비가 오네'를 말하려고 하다가 말실수를 한다면 '눈이 오네'라고 말실수하는 게 '피가 오네'라고 말실수하는 것보다 더 흔하다. 는 이야기인가 보다. 평소에 '불가리스'를 '불가사리'라고 말하는 등 음운적 이유로 말실수가 나오는 경우를 많이 목격하는 편인데, 이건 어떻게 나온 결론인지 좀 궁금하기도 하다.)
위 7과 같은 과정을 거치면, 오로지 cat의 음운 이웃들(cap, hat 등)만 활성화되지 의미적으로 유관한 단어(dog 등)가 활성화되지는 않는다. (혹 의미적으로 유관한 단어가 우연히 음운 이웃이기도 한 경우는 예외)
따라서 음운 이웃 밀도가 높다고 해서 말실수나 발화 지연의 위험성은 커지지 않는 것이다.
반면 듣기 과제는 의미가 아니라 형식에 의해 좌우되기 때문에, (예를 들어 cat을 dog으로 잘못 듣는 일은 상상하기 어렵다) 음운 이웃이 많으면 듣기에 방해가 되는 것이다.
9. 이처럼, 음운 이웃이 많은 단어는 듣는이 입장에선 잘못 들을 위험이 큰데 말하는이 입장에선 빠르고 정확하게 인출하여 말하기가 편하다.
말을 빨리 할 때는 보통 대충 발음하게 되는데, 만약 음운 이웃이 많은 단어를 이렇게 빠르게 대충 발음하면 듣는이 입장에서는 더더욱 잘못 들을 위험이 커질 것이다. 음운 이웃이 많다는 것은 한 음소만 잘못 들어도 곧장 후보 단어가 몇 개씩 생겨난다는 뜻이기 때문이다.
이렇게 양쪽의 이해가 충돌하는 상황에서 화자는 어떤 선택을 할 것인가?
청자 입장에서는 좀 억울하겠지만, Gahl et al.(2011)에 따르면 화자는 음운 이웃이 많은 단어를 말할 때 더 축약된 발음을 사용한다고 한다.
화청자가 힘을 합쳐서 의사소통이란 미션을 성공으로 이끄는 기능주의적인 그림이 익숙한 나로서는 약간 의외인 결과이긴 하다. 어쨌든 논문을 더 제대로 읽어 보면 이해할 수 있겠지...

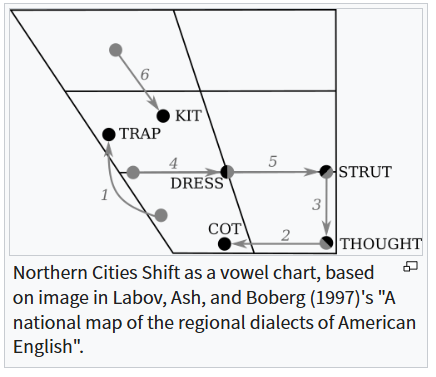
내가 제대로 이해했다면, 위와 같은 모음 공간(vowel space) 그림에서 음운 이웃이 많은 단어일수록 가운데로 몰려 있다는 뜻이 될 것이다.
저자들이 그걸 보여주려는 의도로 실은 그림인지는 모르겠다.
다만 '음소'라는 것이 물리적으로(음성으로, 변이음으로) 실현되었을 때 얼마나 다양한 모습으로 나타날 수 있는지 잘 보여주는 그림 같아서 공유해 본다.
논문 후반부는 아직 못 읽었다. 기회가 되면 마저 읽고 리뷰해 보도록 하겠다.
출처
1. Word lengths are optimized for efficient communication. Piantadosi et al. 2010.
A tendency for this type of "smoothing out" peaks and dips of informativeness is knows as uniform information density and has been observed in choices made during online language production. Formally, uniform information density holds that language users make choices that keep the number of bits of information communicated per unit of time approximately constant. For instance, more informative syllables are produced with longer durations than less informative syllables, meaning that speech rate is modulated to prevent communicating too many bits in a short period.
이 논문 참고문헌 중에 재미있어 보이는 제목이 많다.
1.1.은 위 논문의 핵심 주장.
2. (재인용 출처)
The Smooth Signal Redundancy Hypothesis: A Functional Explanation for Relationships between Redundancy, Prosodic Prominence, and Duration in Spontaneous Speech. Aylett and Turk. 2004.
위 논문 참고문헌인데 재미있어 보인다.
근데 1도 2도 수식이 많아서 내가 정말 제대로 이해할 수 있을진 모르겠다. ㅋ...
3. Why reduce? Phonological neighborhood density and phonetic reduction in spontaneous speech. Gahl et al. 2012.
Phonetic reduction is usually understood to mean not only durational shortening, but also articulatory undershoot resulting in consonant lenition, increased coarticulation, and vowel centralization
4. 같은 논문.
two words are considered neighbors if they differ by deletion, insertion, or substitution of one segment
5. 같은 논문.
words with many neighbors are recognized more slowly and less accurately than words with few neighbors
...
It is easy to imagine a listener mishearing, for example, cat as hat or cap or some other similar-sounding word. In recognition, then, high phonological neighborhood density creates competition between the target and its neighbors.
6, 7, 8, 9 또한 같은 논문.
7~8은 재인용인데 꽤 많이 paraphrase했음에 주의. cat, dog 등의 예는 그대로 가져왔다.
Dell and Gordon 2003의 제목이 재미있다. Neighbors in the lexicon: Friends or foes?
Dell et al. 1997은 Lexical access in aphasic and nonaphasic speakers.
9가 논문의 주된 주장이다.
+ https://www.phon.ox.ac.uk/jpierrehumbert/publications/clopper_JBP_jasa08.pdf
Effects of semantic predictability and regional dialect on vowel space reduction
라는 논문인데
의미적 예측가능성이 영어의 각 방언별로 모음 공간 축소에 어떻게 영향을 미치는지 다룬 내용이다.
초록을 훑어 보니, 본문에서 말했듯이 예측가능할수록 모음이 가운데로 몰리는 현상이 전체적으로 나타나는데,
북부 방언 화자들에게선 'Northern Cities shifting'이라는 모음 추이가 예측가능한 말에서 더 심하게 나타났다는 언급이 인상 깊다.
'언어학' 카테고리의 다른 글
| 내가 5~6살 때 쓴 일기 - 아이의 반모음 인식 (0) | 2025.03.10 |
|---|---|
| ‘그것’이 의존명사구를 가리키는 장면들 - 의존명사구의 실체성? (3) | 2025.01.05 |
| 언어의 발음이란 자음과 모음이 다가 아니다 (3) | 2024.12.29 |
| 수어의 동시성(비선형적 형태통사론) - 언어학자 페이스북에 댓글 달기 (4) | 2024.11.30 |
| 언어의 발음에 존재하는 안전장치, 그리고 언어변화 - 경제성과 명확성의 경쟁, 'splits follow mergers' (2) | 2024.11.29 |